Скачать с ютуб Flink vs Kafka Streams/ksqlDB: Comparing Stream Processing Tools в хорошем качестве
Flink vs Kafka Streams/ksqlDB: Comparing Stream Processing Tools
2 года назад
Скачать бесплатно Flink vs Kafka Streams/ksqlDB: Comparing Stream Processing Tools в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно Flink vs Kafka Streams/ksqlDB: Comparing Stream Processing Tools или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон Flink vs Kafka Streams/ksqlDB: Comparing Stream Processing Tools в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса savevideohd.ru
Flink vs Kafka Streams/ksqlDB: Comparing Stream Processing Tools
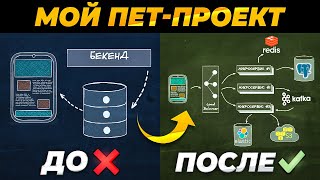
https://cnfl.io/podcast-episode-217 | Stream processing can be hard or easy depending on the approach you take, and the tools you choose. This sentiment is at the heart of the discussion with Matthias J. Sax (Apache Kafka® PMC member; Software Engineer, ksqlDB and Kafka Streams, Confluent) and Jeff Bean (Sr. Technical Marketing Manager, Confluent). With immense collective experience in Kafka, ksqlDB, Kafka Streams, and Apache Flink®, they delve into the types of stream processing operations and explain the different ways of solving for their respective issues. The best stream processing tools they consider are Flink along with the options from the Kafka ecosystem: Java-based Kafka Streams and its SQL-wrapped variant—ksqlDB. Flink and ksqlDB tend to be used by divergent types of teams, since they differ in terms of both design and philosophy. Why Use Apache Flink? The teams using Flink are often highly specialized, with deep expertise, and with an absolute focus on stream processing. They tend to be responsible for unusually large, industry-outlying amounts of both state and scale, and they usually require complex aggregations. Flink can excel in these use cases, which potentially makes the difficulty of its learning curve and implementation worthwhile. Why use ksqlDB/Kafka Streams? Conversely, teams employing ksqlDB/Kafka Streams require less expertise to get started and also less expertise and time to manage their solutions. Jeff notes that the skills of a developer may not even be needed in some cases—those of a data analyst may suffice. ksqlDB and Kafka Streams seamlessly integrate with Kafka itself, as well as with external systems through the use of Kafka Connect. In addition to being easy to adopt, ksqlDB is also deployed on production stream processing applications requiring large scale and state. There are also other considerations beyond the strictly architectural. Local support availability, the administrative overhead of using a library versus a separate framework, and the availability of stream processing as a fully managed service all matter. Choosing a stream processing tool is a fraught decision partially because switching between them isn't trivial: the frameworks are different, the APIs are different, and the interfaces are different. In addition to the high-level discussion, Jeff and Matthias also share lots of details you can use to understand the options, covering employment models, transactions, batching, and parallelism, as well as a few interesting tangential topics along the way such as the tyranny of state and the Turing completeness of SQL. EPISODE LINKS ► The Future of SQL: Databases Meet Stream Processing: https://cnfl.io/the-future-of-sql-epi... ► Building Real-Time Event Streams in the Cloud, On Premises: https://cnfl.io/real-time-event-strea... ► Kafka Streams 101 course: https://cnfl.io/kafka-streams-101-epi... ► ksqlDB 101 course: https://cnfl.io/ksqldb-101-episode-217 ► Kris Jenkins’ Twitter: / krisajenkins ► Join the Confluent Community: https://cnfl.io/confluent-community-e... ► Learn more with Kafka tutorials, resources, and guides: https://cnfl.io/confluent-developer-e... ► Live demo: Intro to Event-Driven Microservices with Confluent: https://cnfl.io/event-driven-microser... ► Use PODCAST100 to get $100 of free Confluent Cloud usage: https://cnfl.io/try-cloud-episode-217 ► Promo code details: https://cnfl.io/podcast100-details-ep... TIMESTAMPS 0:00 - Intro 2:06 - The world of stream processing 6:26 - Flink vs ksqlDB 18:34 - Example use case 20:03 - SQL was built for static data 25:51 - Concept of event time 29:30 - Session-based window joins 35:47 - Processing streaming data with SQL 39:47 - Scaling Kafka Streams/ksqlDB 45:39 - Exactly-once semantics 48:15 - Choosing stream processing tools 53:52 - It's a wrap ABOUT CONFLUENT Confluent is pioneering a fundamentally new category of data infrastructure focused on data in motion. Confluent’s cloud-native offering is the foundational platform for data in motion – designed to be the intelligent connective tissue enabling real-time data, from multiple sources, to constantly stream across the organization. With Confluent, organizations can meet the new business imperative of delivering rich, digital front-end customer experiences and transitioning to sophisticated, real-time, software-driven backend operations. To learn more, please visit www.confluent.io. #streamprocessing #ksqldb #apachekafka #kafka #confluent
Comments