Скачать с ютуб GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models в хорошем качестве
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
2 года назад
Скачать бесплатно GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models в качестве 4к (2к / 1080p)
У нас вы можете посмотреть бесплатно GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models или скачать в максимальном доступном качестве, которое было загружено на ютуб. Для скачивания выберите вариант из формы ниже:
Загрузить музыку / рингтон GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models в формате MP3:
Если кнопки скачивания не
загрузились
НАЖМИТЕ ЗДЕСЬ или обновите страницу
Если возникают проблемы со скачиванием, пожалуйста напишите в поддержку по адресу внизу
страницы.
Спасибо за использование сервиса savevideohd.ru
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
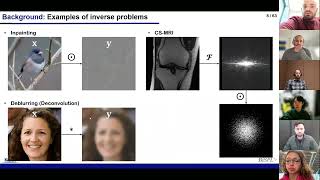
#glide #openai #diffusion Diffusion models learn to iteratively reverse a noising process that is applied repeatedly during training. The result can be used for conditional generation as well as various other tasks such as inpainting. OpenAI's GLIDE builds on recent advances in diffusion models and combines text-conditional diffusion with classifier-free guidance and upsampling to achieve unprecedented quality in text-to-image samples. Try it yourself: https://huggingface.co/spaces/valhall... OUTLINE: 0:00 - Intro & Overview 6:10 - What is a Diffusion Model? 18:20 - Conditional Generation and Guided Diffusion 31:30 - Architecture Recap 34:05 - Training & Result metrics 36:55 - Failure cases & my own results 39:45 - Safety considerations Paper: https://arxiv.org/abs/2112.10741 Code & Model: https://github.com/openai/glide-text2im More diffusion papers: https://arxiv.org/pdf/2006.11239.pdf https://arxiv.org/pdf/2102.09672.pdf Abstract: Diffusion models have recently been shown to generate high-quality synthetic images, especially when paired with a guidance technique to trade off diversity for fidelity. We explore diffusion models for the problem of text-conditional image synthesis and compare two different guidance strategies: CLIP guidance and classifier-free guidance. We find that the latter is preferred by human evaluators for both photorealism and caption similarity, and often produces photorealistic samples. Samples from a 3.5 billion parameter text-conditional diffusion model using classifier-free guidance are favored by human evaluators to those from DALL-E, even when the latter uses expensive CLIP reranking. Additionally, we find that our models can be fine-tuned to perform image inpainting, enabling powerful text-driven image editing. We train a smaller model on a filtered dataset and release the code and weights at this https URL. Authors: Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, Mark Chen Links: TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick YouTube: / yannickilcher Twitter: / ykilcher Discord: / discord BitChute: https://www.bitchute.com/channel/yann... LinkedIn: / ykilcher BiliBili: https://space.bilibili.com/2017636191 If you want to support me, the best thing to do is to share out the content :) If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this): SubscribeStar: https://www.subscribestar.com/yannick... Patreon: / yannickilcher Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2 Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Comments